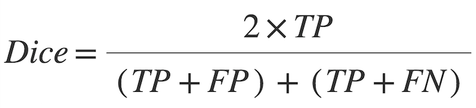Hi,
anyone has checked the label? how many classes are they? loading all the dataset was problematic for my machine.
thank you
Hi,
anyone has checked the label? how many classes are they? loading all the dataset was problematic for my machine.
thank you
Hi @Khariwa. The dataset will have varying numbers of classes depending on the features that are in the particular volume. You should generally expect between 5 and 25 classes in each volume.
Also, when you call numpy.load() ensure that allow_pickle=True. If this argument is not included, attempts to load the volumes will result in an error.
Thanks!
Onward Team
Hi,
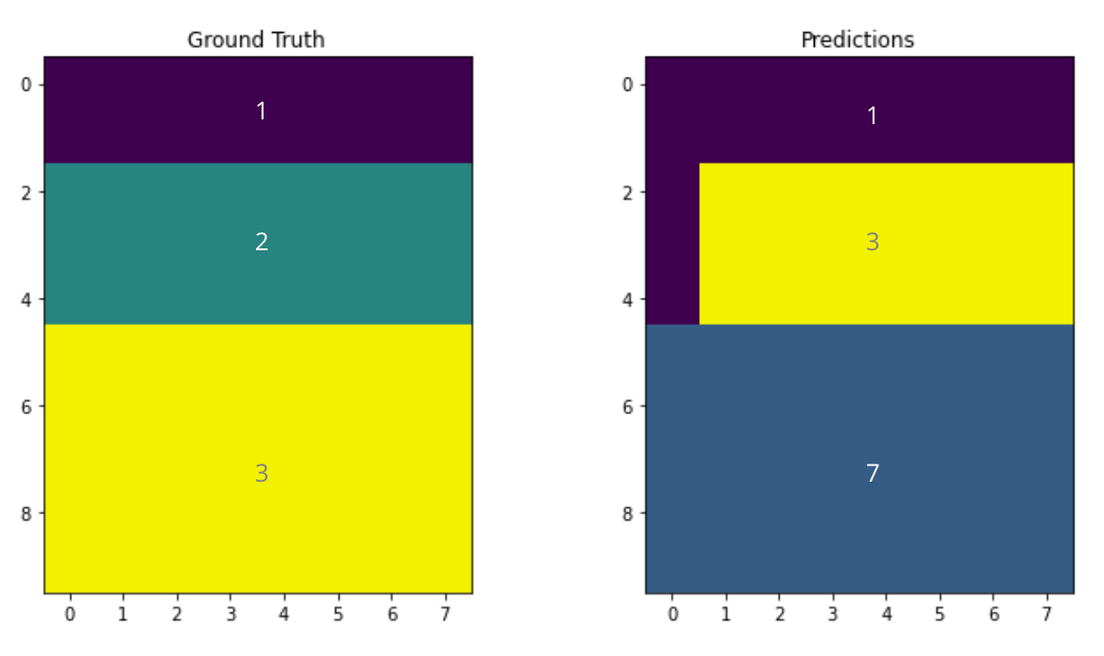
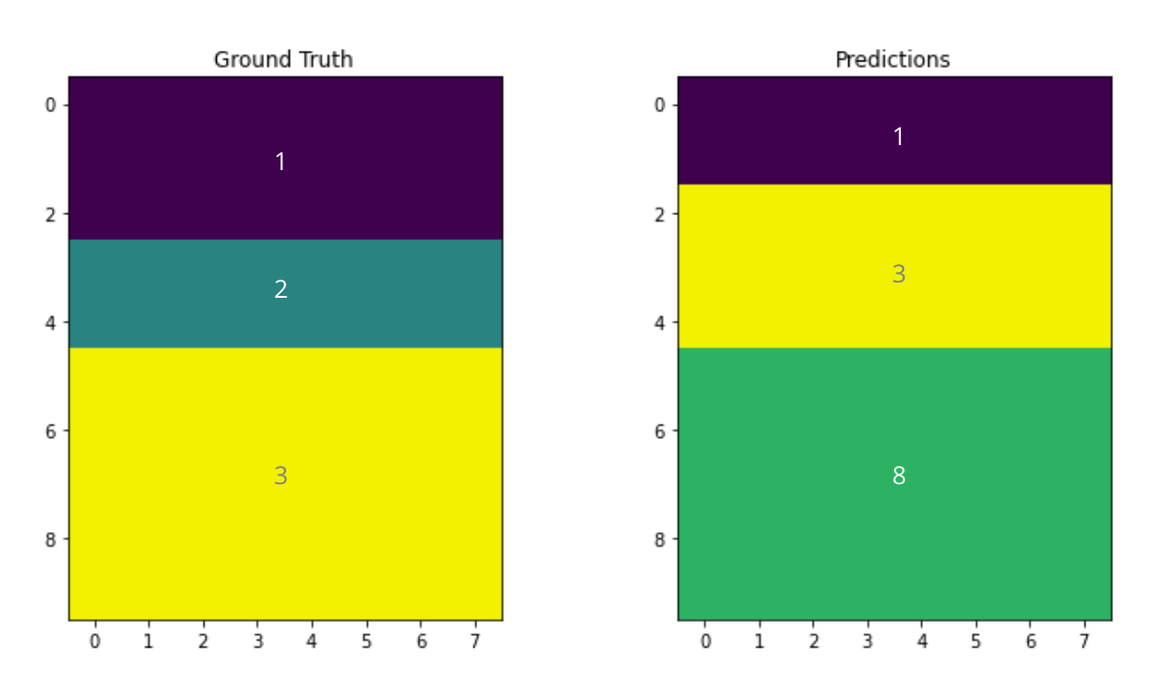
I would like to ask if the value of label is matter? or can I assign different values of label as long the layer segmentation is correct from position point of view? for example, the first image is ground truth and second image is my prediction. The segmentation part from prediction is perfectly resemble actual segmentation but the class assignment was different. will it get the perfect score?
Hi @Khariwa. Thanks for the question. You are free to assign different values for labels as long as the layer segmentation is correct. The scoring algorithm takes this into account when scoring.
Keep up the good work!
Onward Team
Thank you for the information. Would you mind sharing the code for the scoring? I wonder if it is same with dice score in other competition or modified.
Thank you
Regards,
Ramdhan
Hi @Khariwa. We’d be happy to share the code. We are calculating a dice score.
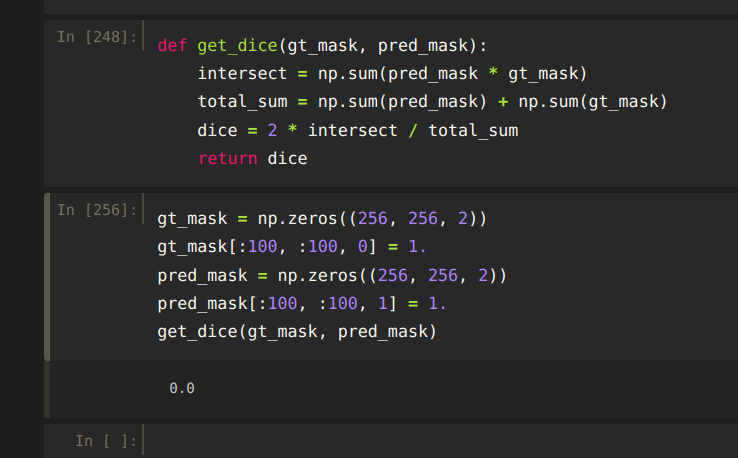
def get_dice(ground_truth_mask, prediction_mask):
intersect = np.sum(pred_mask * gt_mask)
total_sum = np.sum(pred_mask) + np.sum(gt_mask)
dice = 2 * intersect / total_sum
return dice
Just to clarify, the dice function that you have provided does not score for the segmentation if the class is wrong, like in the image below, I predicted the same segmentation region but on a different class channel and got the score 0.
Does this get accounted for in the preprocessing of the scoring function? If yes, then what if my predictions are shifted by 1 channel by model’s fault, will I get 0 score?
Besides this, is the public/prediction leaderboard score hidden? asking because everyone is on the same sample notebook score
Hi @Harshit_S thanks for following up on this. We took a look at the code you provided along with the dice function that we provided. When we run the following:
import numpy as np
def get_dice(ground_truth_mask, prediction_mask):
intersect = np.sum(pred_mask * gt_mask)
total_sum = np.sum(pred_mask) + np.sum(gt_mask)
dice = 2 * intersect / total_sum
return dice
gt_mask = np.zeros((256,256,2))
gt_mask[:100, :100, 0] = 1
pred_mask = np.zeros((256,256,2))
pred_mask[:100, :100, 0] = 1
get_dice(gt_mask, pred_mask)
The output is a value of 1.0, and if we change the intersection to:
gt_mask = np.zeros((256,256,1))
gt_mask[:100, :100, 0] = 1
pred_mask = np.zeros((256,256,1))
pred_mask[50:150, 50:150, 0] = 1
get_dice(gt_mask, pred_mask)
The output is 0.25 as we would expect. Can you try this again in a fresh notebook to see if you can reproduce our results?
The predictive leaderboard is currently active, and as of 26 December 2023 the top score is 0.32.
Keep up the great work!
Onward Team
IMO @Harshit_S 's question was about giving a layer a different label because you mentioned that “You are free to assign different values for labels as long as the layer segmentation is correct.”
So, he used
gt_mask[:100, :100, 0] = 1
and
pred_mask[:100, :100, 1] = 1
While you are talking about
gt_mask[:100, :100, 0] = 1
and
pred_mask[50:150, 50:150, 0] = 1
which is not the same.
We are sorry for misunderstanding around the previous question.
The get_dice() function is not intended to be used in the way you shared above. This function constitues an integral part of larger scoring algorithm. The full evaluation pipeline takes into account the possible mismatch between ‘ground truth - prediction’ label values and thus contains several preprocessing steps to address the problem.
Although we provided an overview of the scoring pipeline in the Evaluation part of challenge description, to prevent further ambiguity around it, here we will describe the scoring logic in more details on a simple example.
As an example, let’s take two 3-D arrays (Ground Truth and Prediction volumes) of the same shape: 2x10x8.
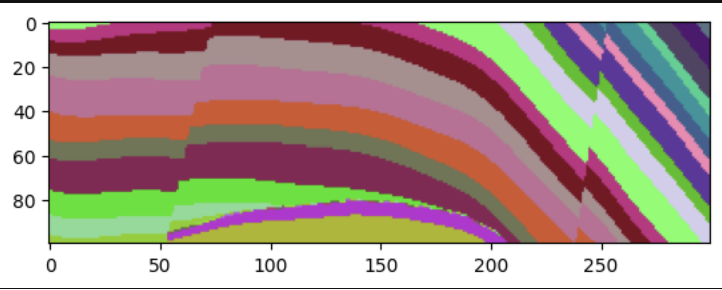
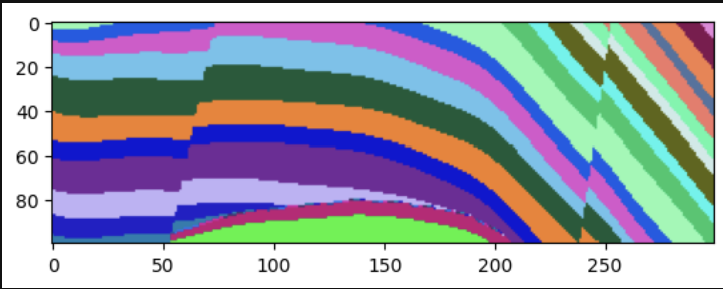
Various ML/DL models may follow different logic of labelling during segmentation process. Let’s take a look at a few slices of example data to identify possible corner cases:
As we see, the segmentation masks are quite similar to ground truth ones. At the same time, the segmentation model assigned labels different from ground truth. On this example we also see, that the bottom layer in predictions has different labels assigned on different slices (it can be a case if a model predicts 2-D data).
In order to address these problems, the scoring pipeline goes through each pair of ground truth and prediction volume slices, maps the corresponding labels by computing the dice score for each pair of labels and selects pairs with the highest scores. This is where the above mentioned get_dice() function is being used.
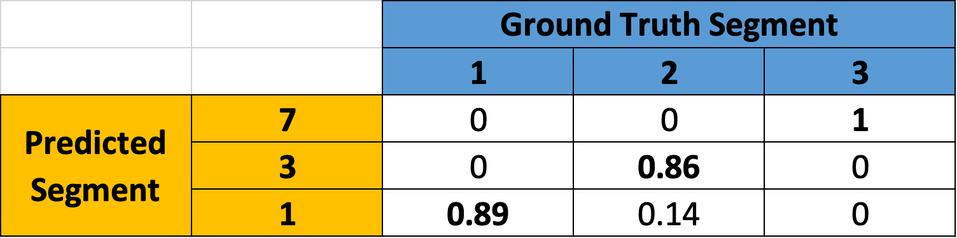
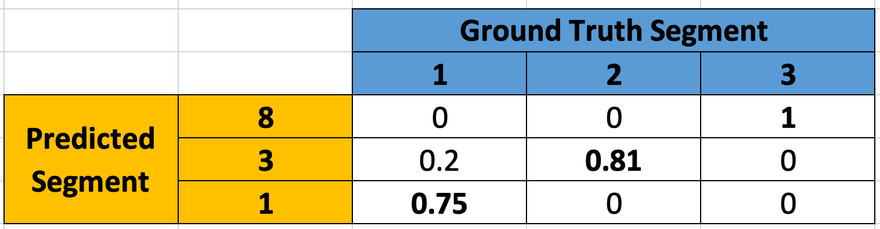
Coming back to the example data, to map the label pairs for the first slice shown above, the scoring algorithm creates the following dice matrix:
To extract the first pair of matched labels, the combination with the highest dice score is taken (GT segment ‘3’ is mapped to Predicted segment '7’ with the dice score of 1). After that, the mapped labels are removed from the matrix to avoid mapping the same segment twice.
Once the matrix is updated, the algorithm looks for the next highest dice score and gets the combination (GT segment ‘1’ is mapped to Predicted segment ‘1’ with the dice score of 0.89).
The algorithm goes on until all ground truth segments (labels) are mapped to their predicted equivalents for this slice.
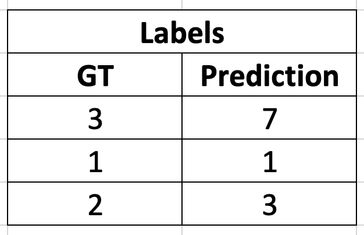
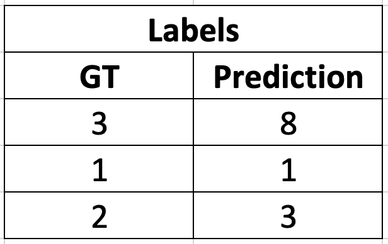
At the end of this step, we have the following mapping:
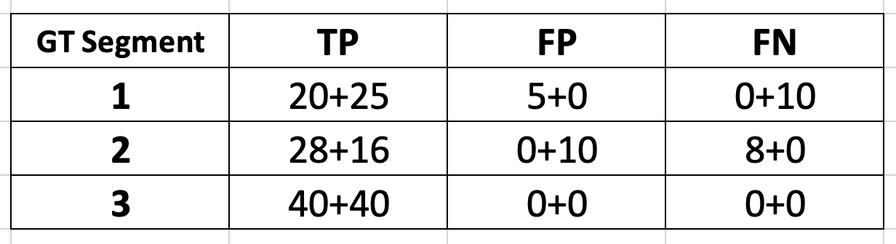
Since seismic layers (horizons) are three-dimensional objects, we use a 3-dimensional evaluation of each layer. For this, we need to cache some intermediate metrics for each layer, which will later be needed to calculate the 3D dice score.
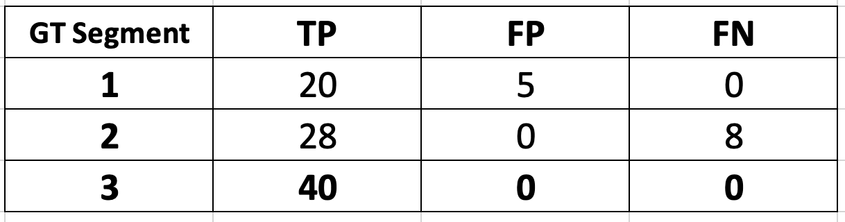
Using the mapping results from the previous step, we compute and cache the intermediate metrics for each ground truth layer on the current slice. At the end of this step, we have the following metrics stored:
After that, the algorithm is done with the 1st slice and keeps doing the same steps for the rest of the slices. Let’s take a look at some key stages of the 2nd slice processing.
As you can see, the intermediate metrics are being updated after each slice to collect all necessary information about how well each layer was segmented. If the algorithm comes across a new GT layer label (e.g. ‘4’) in one of the following slices , it adds it to the intermediate metrics dictionary and starts tracking its metrics in the same way.
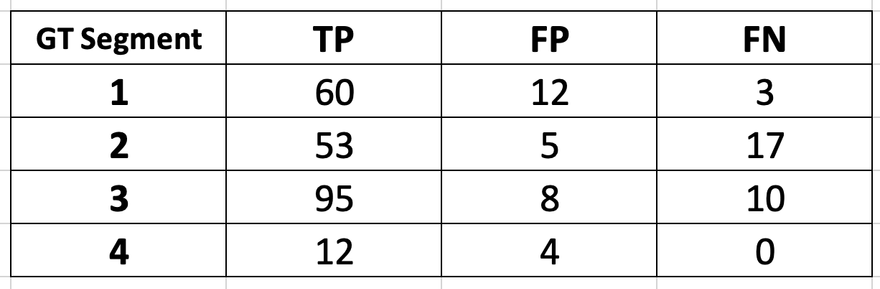
Let’s say that after the final slice is processed, we have the following final metrics for each layer:
We use these metrics to compute the dice score for each layer using the Dice coefficient formula shown above:
Dice scores
Segment 1: 0.889
Segment 2: 0.828
Segment 3: 0.913
Segment 4: 0.857
At the final stage of volume processing, the algorithm calculates average dice score of all segments present in the volume:
Volume Avg Dice Score (VADS): (0.889 + 0.828 + 0.913 + 0.857) / 4 = 0.87
The scoring algorithms does the steps 1-4 for all 50 volumes in test dataset. After that, the final submission score is obtained by averaging across all 50 VADSs.
Onward Team
Thank you for such a wonderful explanation, what would happen if I am predicting more classes than ground truth? Because, if it selects/maps the closest dice based on ground-truth, that would mean I can make 100s of “Predicted Segment” and it will only account for the prediction that best fits each “Ground Truth Segment” and ignore the rest of my predictions. That would be a flaw in the metric?
Hey @Harshit_S. Your assumptions about how the scoring algorithm would react to “over segmentation“ are correct. Let us explain the idea.
Say, there are 5 ground truth segments on a slice. Some model (not very robust one) may predict 100 different segments for the slice, instead of just 5. In this case, the scoring algorithm will apply the mapping logic that we explained above, to choose top 5 predicted segments (out of 100) which fit the ground truth segments best. The rest of 95 predicted segments will be ignored.
The main idea behind it, is that every extra (redundantly) predicted segment is a false negative for one or more ground truth segments. As we explained above, false negatives are taken into account when we calculate the dice score for each Ground Truth - Prediction segment pair, and so each extra segment will decrease the corresponding dice scores proportionally to its size (area). Thus, there is no need to impose additional penalty for “over segmentation”.
Onward Team